Proxem Studio
Glean Insights from Your Textual Data with Natural Language Processing
AI-Powered Semantic Analysis of Textual Data
Proxem Studio solutions deliver a combination of natural language processing and machine learning technologies to better understand customer expectations, market trends and other important factors, ensuring the right products reach the right people at the right time.
Proxem Insight
Textual Data Analysis for Customer and Employee Experience
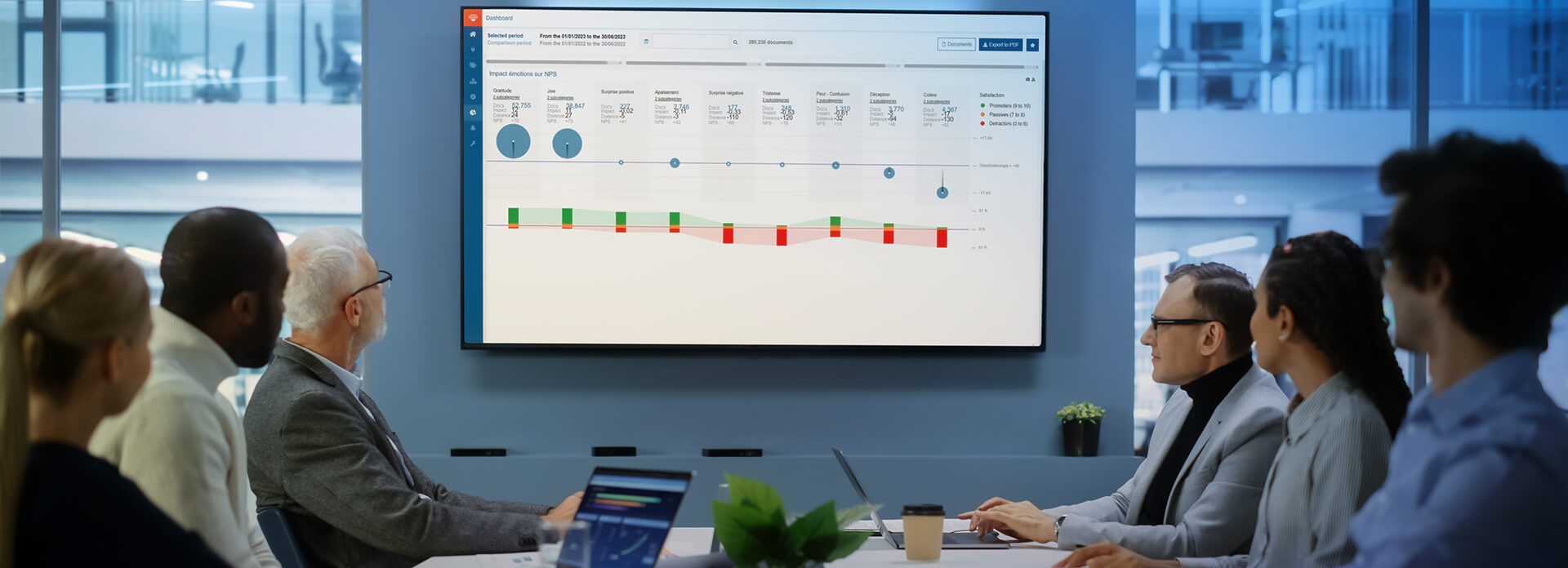
- Identify and analyze brand attributes and drivers of satisfaction. Proxem Studio semantic and sentiment analysis software enables real-time analysis of all customer conversations and feedback to identify key moments in the customer journey with their related topics, tones and reasons for satisfaction and dissatisfaction. By analyzing multilingual text from any source (emails, web reviews, satisfaction surveys, social networks, brand forums, documents and more), it allows users to obtain a quantitative overview, detect topics and identify weak signals.
- Improve key performance indicators. Focus on KPIs and high value-added tasks to improve customer satisfaction indicators (including net promoter score, customer retention and average resolution time) and measure the performance of actions on loyalty, conversion, brand attributes, brand image, operating costs, churn rate and more. Efficiently share information with all employees. Aggregate all customer feedback to gain a 360-degree omnichannel view of the voice of the customer through connectors and available application programming interfaces.
Proxem Knowledge
Information Extraction and Knowledge Management for Improved Efficiency
-
Optimize the information search. Easily find the right information at the right time thanks to a semantic search engine perfectly adapted to company data, whatever the document language and formats.
-
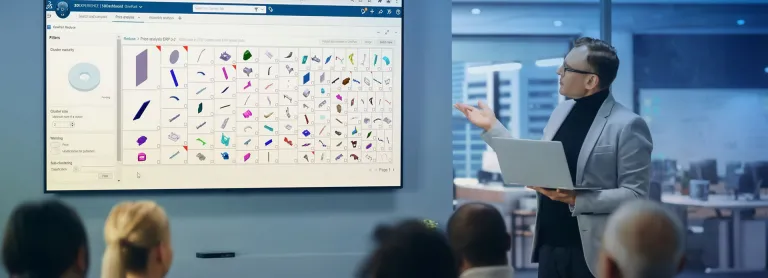
Produce knowledge through semantic analysis of documentary databases. Enrich business ontologies and repositories from text data thanks to embedded AI. From market mapping to contract or patent analysis or scientific research, Proxem Studio allows users to produce new knowledge that can be activated whatever the corpus (entity and relationship extraction, classification, clustering, correlation analysis, weak signal detection, and more).
- Streamline business processes with information extraction. Extract from text the key information required to gain fluidity in business processes, regardless of the field: clause detection in contracts, extraction of people, places, organizations, anonymization, document information and more. AI helps streamline business processes and improve efficiency.
Start Your Journey
Thanks to all these results, we were able to calculate the failure rates of our equipment.
Also Discover

Unleash Continuous Innovation with Information Intelligence
Decrease Risks with Product Part Sourcing & Standardization Intelligence
Put Your Company Information to Work as a Customer Engagement Machine

Maximize Product Availability with Data-driven Asset Operations Management
Learn What NETVIBES Can Do for You
Speak with a NETVIBES expert to learn how our solutions enable people at all levels of the enterprise to make better, more informed business decisions.
Get Started
Courses and classes are available for students, academia, professionals and companies. Find the right NETVIBES training for you.
Get Help
Find information on software & hardware certification, software downloads, user documentation, support contact and services offering