Proxem Studio
Аналитика на основе текстовых данных благодаря обработке естественных языков
Семантический анализ текстовых данных на базе ИИ
Решения Proxem Studio объединяют обработку естественных языков и технологии машинного обучения для лучшего понимания ожиданий клиентов, рыночных тенденций и других важных факторов, что гарантирует своевременную доступность нужных продуктов нужным людям.
Proxem Insight
Текстовый анализ данных для взаимодействия с клиентами и сотрудниками
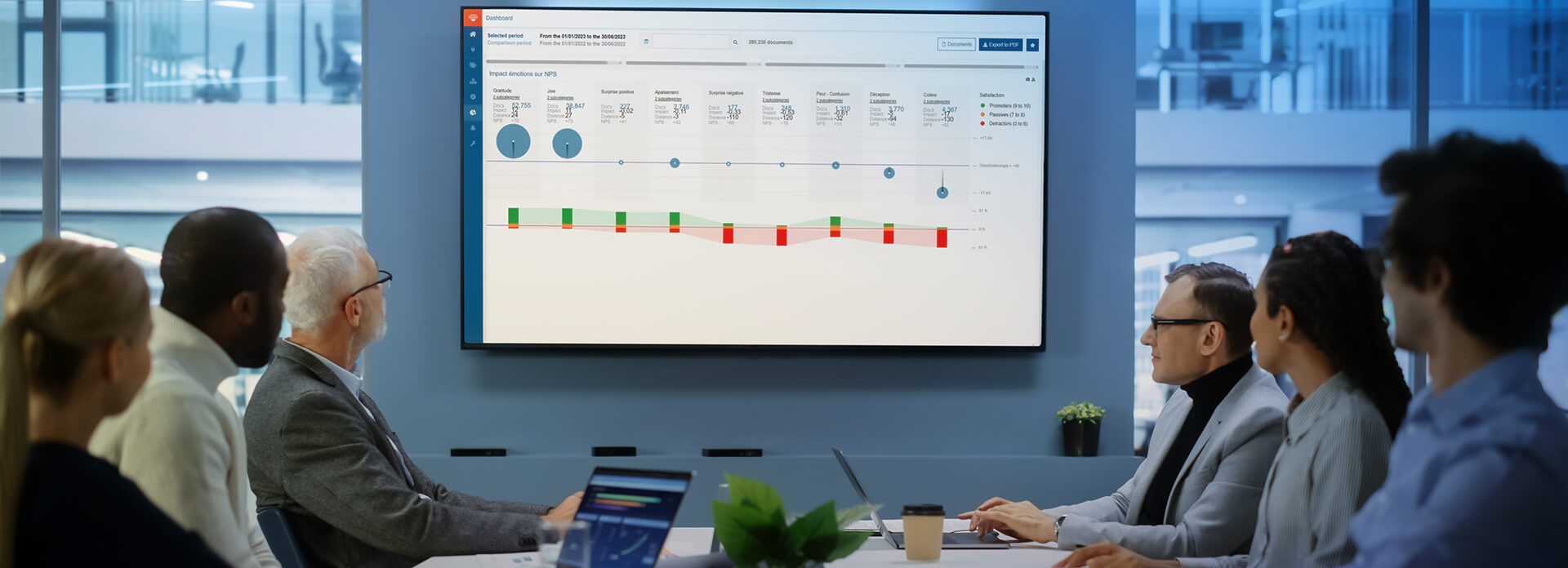
- Определение и анализ атрибутов бренда и факторов, улучшающих удовлетворенность клиентов. Семантический анализ и анализ эмоциональной окраски в Proxem Studio позволяют анализировать беседы и отзывы клиентов в режиме реального времени для определения ключевых моментов взаимодействия и связанных с ним тем, коннотаций и причин удовлетворенности и неудовлетворенности. Анализ многоязычного текста из любого источника (электронная почта, обзоры веб-ресурсов, исследования удовлетворенности, социальные сети, форумы брендов, документы и многое другое) позволяет пользователям получить обзор количественных данных, определить темы и обнаружить слабые сигналы.
- Повышение ключевых показателей эффективности. Можно сосредоточиться на КПЭ и стратегически важных задачах, чтобы повысить показатели удовлетворенности клиентов (включая оценку потребительской лояльности, уровень удержания клиентов и среднее время разрешения), а также измерить эффективность действий (лояльность, конверсия, атрибуты бренда, логотип, операционные затраты, уровень оттока и др.). Эффективный обмен информацией со всеми сотрудниками. Объединение всех отзывов клиентов для получения полного многоканального представления о потребностях клиентов благодаря соединителям и доступным интерфейсам прикладного программирования.
Proxem Knowledge
Извлечение информации и управление знаниями для повышения эффективности
-
Оптимизация поиска информации. Легкий и своевременный поиск нужной информации благодаря механизму семантического поиска, который идеально адаптируется к корпоративным данным вне зависимости от языка и формата документов.
-
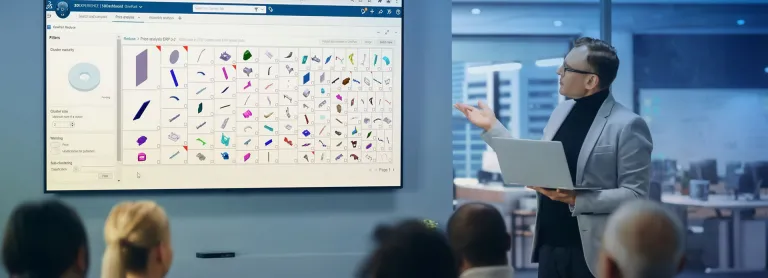
Формирование знаний с помощью семантического анализа баз данных документов. Усовершенствование бизнес-онтологий и репозиториев текстовых данных благодаря встроенному ИИ. От сопоставления рынков до анализа договоров, патентов и научных исследований — Proxem Studio позволяет формировать новые знания, которые можно использовать вне зависимости от типа базы текстов (определение объектов и связей, классификации, кластеризация, корреляционный анализ, обнаружение слабых сигналов и др.).
- Оптимизация бизнес-процессов благодаря извлечению информации. Извлечение из текста ключевой информации, необходимой для обеспечения прозрачности бизнес-процессов независимо от сферы деятельности: определение пунктов договоров, извлечение данных о людях, местах, организациях, анонимности, документах и многое другое. ИИ помогает оптимизировать бизнес-процессы и повысить эффективность.
Начните свой путь
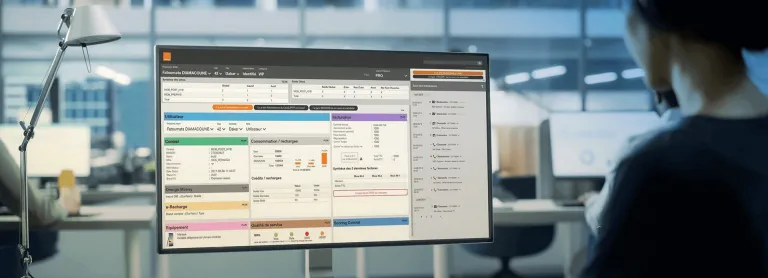
Благодаря всем этим результатам мы смогли рассчитать частоту отказов нашего оборудования.
Дополнительно

Непрерывное внедрение инноваций благодаря анализу данных
Снижение рисков с помощью аналитики снабжения деталей изделий и стандартизации
Использование корпоративной информации в качестве средства привлечения клиентов

Максимальная доступность продуктов благодаря управлению операциями с активами на основе данных
Узнайте о преимуществах NETVIBES для вашего бизнеса
Свяжитесь с экпертом NETVIBES, чтобы узнать, как наши решения позволяют сотрудникам на всех уровнях предприятия принимать более обоснованные бизнес-решения.
Начало работы
Для студентов, ученых, профессионалов и компаний доступны курсы и классы. Найдите подходящий вам обучающий курс NETVIBES.
Помощь
Здесь вы найдете сведения о сертификации программного и аппаратного обеспечения, файлы для скачивания программного обеспечения, пользовательскую документацию, контакты службы поддержки и предлагаемые услуги