Proxem Studio
自然言語処理でテキスト・データからインサイトを収集
テキスト・データに関する AI 駆動セマンティック解析
Proxem Studio ソリューションは、自然言語処理と機械学習の各テクノロジーを併用して、顧客の期待、市場動向、その他の重要な要因をより深く理解し、適切な製品が適切なタイミングで適切なユーザーに届くようにします。
Proxem がもたらすインサイト
顧客や従業員の体験のためのテキスト・データ解析
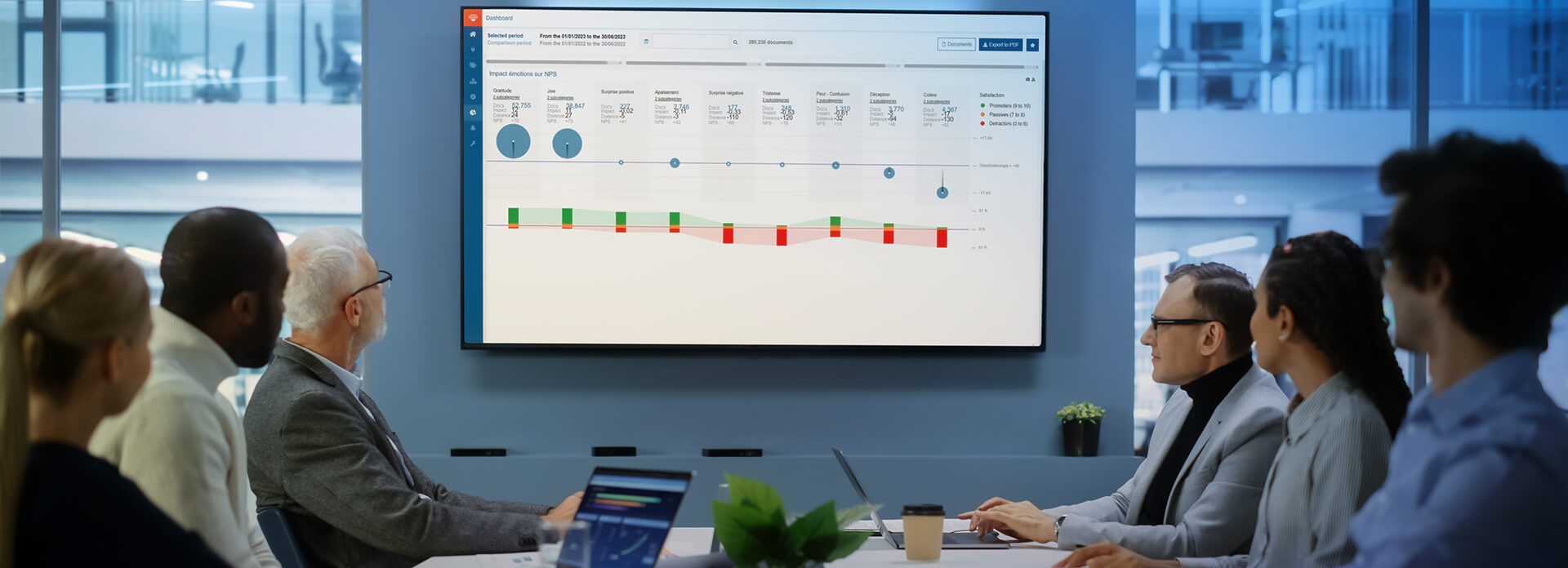
- ブランドの特性と満足度の要因を特定し、解析する。Proxem Studio のセマンティック & センチメント解析ソフトウェアを使用すると、顧客との会話とフィードバックをすべてリアルタイムで解析して、顧客の購買プロセスにおける重要な瞬間と、それに関連するトピック、温度感、満足・不満の原因を特定できます。あらゆるソース(電子メール、Web レビュー、満足度調査、ソーシャル・ネットワーク、ブランド・フォーラム、ドキュメントなど)の多言語テキストを解析することで、定量的な概要の取得、トピックの検出、微細な兆候の識別が可能になります。
- 主要なパフォーマンス指標を改善する。KPI を重視し、顧客満足度指標(ネット・プロモーター・スコア、顧客定着率、平均解決時間など)の改善や、ロイヤルティ、コンバージョン、ブランド属性、ブランド・イメージ、運用コスト、解約率などの成果の測定といった付加価値の高いタスクに取り組むことができます。情報をすべての従業員と効率的に共有します。コネクターと利用可能なアプリケーション・プログラミング・インターフェースを通じて、すべての顧客フィードバックを集約して、顧客の声をあらゆる角度から把握します。
Proxem がもたらすナレッジ
情報の抽出とナレッジ・マネジメントにより、効率性を向上
-
情報検索を最適化する。企業のデータに完全に適合したセマンティック検索エンジンにより、ドキュメントの言語や形式に関係なく、適切な情報を適切なタイミングで簡単に検索できます。
-
ドキュメント・データベースのセマンティック解析を通じてナレッジを得る。組み込み AI により、ビジネスのオントロジーやリポジトリをテキスト・データから増大できます。マーケット・マッピング、契約/特許の解析、科学的研究などの分野で Proxem Studio を使用すれば、コーパスの対象(エンティティと関係性の抽出、分類、クラスタリング、相関関係の解析、微細な兆候の検出など)に関係なく、実際に役に立つ新しいナレッジを生み出すことができます。
- 情報抽出によりビジネス・プロセスを合理化する。分野(契約書の条項の検出、人材、場所、組織、匿名化、ドキュメント情報の抽出など)に関わらず、ビジネス・プロセスを円滑に進めるために重要な情報をテキストから抽出します。 AI を利用することでビジネス・プロセスを合理化し、効率を上げることが可能になるのです。
さあ、始めましょう
結果を利用して、機器の故障率を算出できました。
その他の情報

インフォメーション・インテリジェンスで継続的にイノベーション
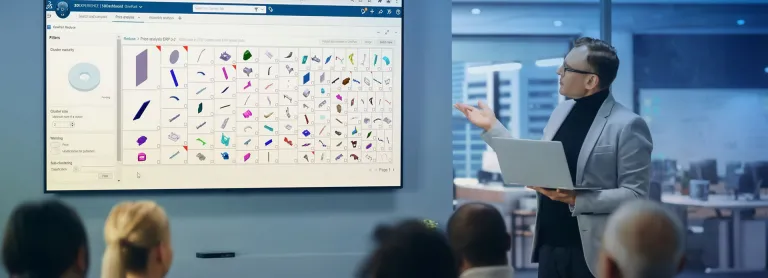
製品部品調達と標準化のインテリジェンスでリスクを軽減
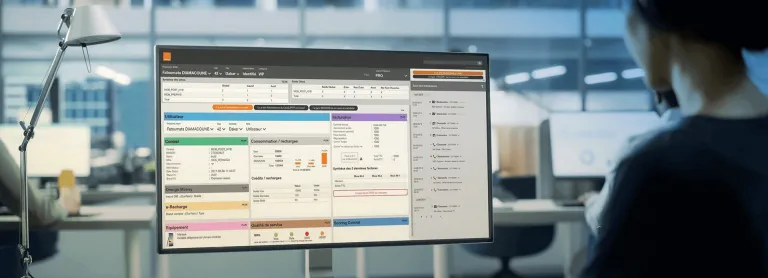
自社の情報を顧客エンゲージメント・マシンとして機能させる

データ主導型の資産運用管理により、製品の可用性を最大化
NETVIBES のソリューションの詳細
企業のあらゆる階層で、より多くのより優れた情報に基づいてビジネス上の意思決定を下すことができます。ダッソー・システムズのソリューションがどう役立つかについて、NETVIBES 担当技術者がご説明します。
使用開始
学生、教育機関、専門家、企業向けのコースとクラスをご用意しています。お客様に最適な NETVIBES トレーニングを受講してください。
サポートの利用
ソフトウェアやハードウェアの資格認定、ソフトウェアのダウンロード、ユーザー・マニュアル、サポート連絡先、サービス・オファリングに関する情報はこちら